
Resources
Browse our collection of latest insights, essential new research, and practical tips.


94% of Ransomware Victims Have Their Backups Targeted By Attackers
According to a new study from Sophos, those whose backups are compromised will pay 98% of the demanded sum, on average.
Backups Breached With Phobos Ransomware – according to the FBI and CISA
The FBI and Cybersecurity and Infrastructure Security Agency (CISA) released a joint CSA about Phobos Ransomware, which hunts for backups after the exfiltration phase. In 2024,

Threat Actors Target Network-Attached Storage (NAS), According to Cyber Security Agency of Singapore
In recent weeks, threat actors have performed logins to NAS systems, by using administrator accounts through valid user credentials, exploiting vulnerabilities in the NAS systems, and

The CISOs Guide To ISO/IEC 27040: Storage Security
The release of ISO/IEC 27040:2024 provides an overview, analysis, and guidance for the security of storage & backup systems.
Akira Ransomware Attackers Are Wiping NAS And Backup Devices
The Finish National Cybersecurity Center (NCSC-FI) detected increased Akira Ransomware activity, targeting companies’ network-attached storage (NAS), while wiping their backups. The agency says that the threat actor’s
Norton Healthcare Discloses Storage Breach After Summer Ransomware Attack
In a news release on Dec. 12, Norton Healthcare said their investigation found the unauthorized access occurred to “certain network storage devices.” The storage devices were
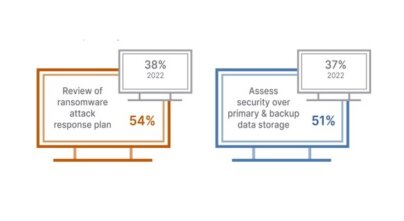
Internal Auditors Focusing On The Security of Backup & Data Storage
Efforts to combat ransomware are a major focus for Audit teams. 54% of auditors have reviewed a ransomware attack response plan, and 51% have assessed backup
Allen & Overy Hit By Ransomware Attack; Impacting Their Storage Systems
The global law firm confirmed it had experienced a cyber security incident, from hacking group Lockbit, which impacted a number of storage servers. Lockbit has been
DBS Bank Suspend All Changes To IT Systems, Except Those Related To Security, Regulatory Compliance And Risk Management
DBS and Citibank experienced outages on October 14, 2023. Both banks immediately activated IT disaster recovery and business continuity plans. However, they encountered technical issues which
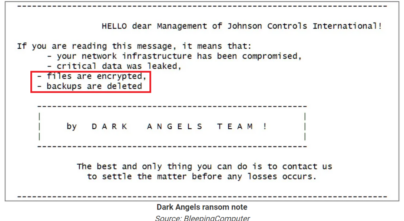
Johnson Controls International Suffers Massive Ransomware Attack – Including Deleted Backups
In the ransom note sent by Dark Angels, the ransomware group, it included the following details: “Files are encrypted. Backups are deleted”.
Hackers weaponizing MinIO storage system flaws to target corporate networks
Hackers are exploiting two recent vulnerabilities on MinIO, an Amazon S3 cloud storage service, to breach object storage systems and access private information, execute arbitrary code, and potentially

Ransomware exploits flaws in enterprise backup software to attack infrastructure
A known ransomware gang – knows as Cuba – is exploiting a high-severity vulnerability in Veeam to deploy malware to their targets and steal login credentials.

4 Urgent Reasons To Harden Your Storage & Backups
Download this short infographic to discover 4 major reasons why you need to harden your storage & backups.
New Ransomware Operation, NoEscape, Gains Momentum In Targeting Backups
NoEscape is an emerging ransomware group that executes commands to delete shadow copies and system backups, to hinder recovery efforts, eliminating potential restoration options.
CISA Warns Customers Of Zyxel NAS Products That The Recently Patched Critical Vulnerability Has Been Exploited In Attacks
The US Cybersecurity and Infrastructure Security Agency (CISA) warns that a recently patched critical vulnerability CVE-2023-27992 affecting network-attached storage (NAS) products made by Zyxel has been

93% Of Cyber Attacks Target Backup Storage To Force Ransom Payment
Attackers are successful in debilitating their victims’ ability to recover in 75% of those events, reinforcing the criticality of security posture management to ensure backup repositories
Dish Network, the US media provider, most likely paid a ransom after being hit by ransomware attack
The assailants gained access to the Windows domain controllers, encrypting VMware ESXi servers and backups, causing a massive outage… Dish has since been slapped with multiple class-action lawsuits alleging their poor cybersecurity and IT infrastructure.
Feds Warn of Rise in Attacks Involving Veeam Software Flaw
Federal authorities are warning the healthcare sector of a rise in cyberattacks against Veeam backup application. The attacks appear tied to exploitation of a high-severity vulnerability

RTM Locker’s First Linux Ransomware Strain Targeting NAS and ESXi Hosts
The threat actors behind RTM Locker have developed a ransomware strain that’s capable of targeting Linux machines, infecting NAS and ESXi Hosts

Russian Cybercrime Group FIN7 Caught Exploiting Recent Veeam Vulnerability
The high-severity vulnerability was first published in March 2023. It enables an unauthenticated user who has accessed the Veeam backup network perimeter to get their hands
Storage Accounts At Risk With New Microsoft Azure Vulnerability
Newly discovered “By-Design” flaw in Microsoft Azure could expose storage accounts to Hackers
The ALPHV Ransomware Operation Exploits Veritas Backup Exec Bugs For Initial Access
U.S. Cybersecurity and Infrastructure Security Agency (CISA) increased its list of security issues that threat actors have used in attacks, three of them in Veritas Backup Exec exploited to deploy ransomware.
Ransomware Group Exploits Security Risks in Backups with Their Own Network-Scanning & Information-Stealing Tool
The Play Ransomware group’s tool, called Grixba, checks for the presence of backup software. Another tool they created, called VSS Copying Tool, creates system snapshots and

Data Storage Company Western Digital Suffered Network Security Incident
The security breach appears to have been linked to ransomware, but so far, no major ransomware group has claimed responsibility for the attack.
Serious Vulnerability Patched in Veeam Data Backup Solution
Veeam this week announced patches for a severe vulnerability in its Backup & Replication solution. CVE-2023-27532 allows an unauthenticated user to request encrypted credentials


Hackers Steal GoTo Customers’ Backups And Encryption Key
GoTo (formerly LogMeIn) is warning customers that threat actors stole encrypted backups containing customer information and an encryption key for a portion of that data. GoTo chief executive Paddy Srinivasan confirmed the security breach was far worse than originally reported.

3 Critical Vulnerabilities In Veeam Backup & Replication Solution Allow Ransomware To Steal Credentials & Encrypt Your Backups
Several threat actors were seen advertising the fully weaponized tool to exploit several critical and high-severity vulnerabilities affecting Veeam
Ransomware Group Steals Veeam Credentials And Encrypts Backups
Noberus ransomware affiliates Noberus (also known as BlackCat, ALPHV) are using data-stealing malware to steal passwords held by Veeam backup software. This is being used by the Colonial Pipeline ransomware group.
Brocade Vulnerabilities Impact Storage Solutions of Several Major Companies
The storage solutions of HPE and NetApp are also affected by these vulnerabilities


Fujitsu Storage Vulnerabilities Could Enable Attackers To Destroy Backups
Any attacker with control over the system can read, modify and potentially destroy the entire virtual backup tapes, which could be used as an initial stage


Deadbolt – the ransomware that goes straight for your backups
More than 1,000 QNAP devices have been infected with the Deadbolt ransomware in the last week

Deadbolt Ransomware Targets NAS Devices
Storage solutions provider issued a warning to alert users of Deadbolt ransomware attacks targeting its NAS appliances. This is the second NAS devices firm targeted by

Critical Veeam Backup Vulnerabilities Exposed Users To Ransomware
The security holes could be exploited to execute code remotely, without authentication.

QNAP NAS Devices Hit In Surge Of ech0raix Ransomware Attacks
Users of QNAP network-attached storage (NAS) devices are reporting attacks on their systems with the eCh0raix ransomware, also known as QNAPCrypt.
Storage Devices From Several Major Vendors Affected By Vulnerabilities Discovered
Western Digital had updated its SanDisk SecureAccess product to address vulnerabilities that can be exploited to gain access to user data.

MSSPs Among Hardest Hit by Cyberattacks Targeting Backup Vulnerabilities
Cyber attackers are making a ‘beeline’ for backup servers to disable or corrupt files.

Who Is Hive Ransomware?
The ransomware gang is known to seek out and delete any backups, preventing them from being used by the victim to recover their data.

Conti Ransomware Expands Ability To Blow Up Backups
The Conti ransomware gang has developed novel tactics to demolish backups, especially the Veeam recovery software.

Synology Warns Of Malware Infecting NAS Devices With Ransomware
Synology has warned customers that the StealthWorker botnet is targeting their network-attached storage (NAS) devices.
Security And Storage Go Hand In Hand
You must secure the network, the endpoints, and the data. You also need to keep your storage units secure and updated.
Ransomware Attacks Target Backup Systems, Compromising The Company ‘Insurance Policy’
“If you can’t access backup, you aren’t going to be able to restore files and you’re more likely to pay the ransom.”
Ransomware Victims That Have Backups Are Paying Ransoms To Stop Hackers Leaking Their Stolen Data
Ransomware attacks are proving more lucrative for cyber criminals as even organizations that can restore from backups are paying ransom demands.
Your Backup And Restore Process Is Broken – Here’s How To Fix It
Don’t wait for a ransomware attack to expose backup flaws. These eight steps will put you on the path for reliable data restores.





























































Talk To An Expert
It’s time to automate the secure configuration of your storage & backup systems.