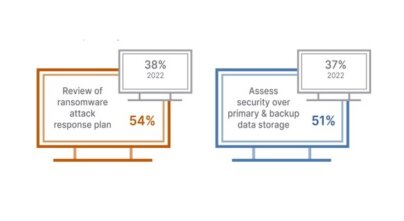
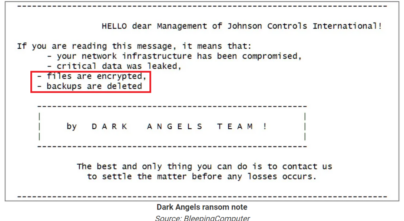
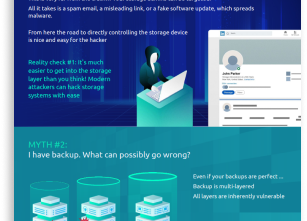
The 2025 Security Maturity of Storage & Data Protection Systems
The third edition of The 2025 Security Maturity of Storage & Data Protection Systems assessed 323 environments with 11,435 storage and backup devices from leading providers…
Read more