Automated Storage & Backup Hardening
Secure Your Storage & Backups
When did you last check the configurations of your storage & backup systems? Now you can automatically detect and fix all security risks – to harden your storage & backup systems against ransomware.
Respected Brands Trust Continuity™
StorageGuard
The industry’s ONLY cybersecurity solution for enterprise storage & backup systems, helping you secure your data.
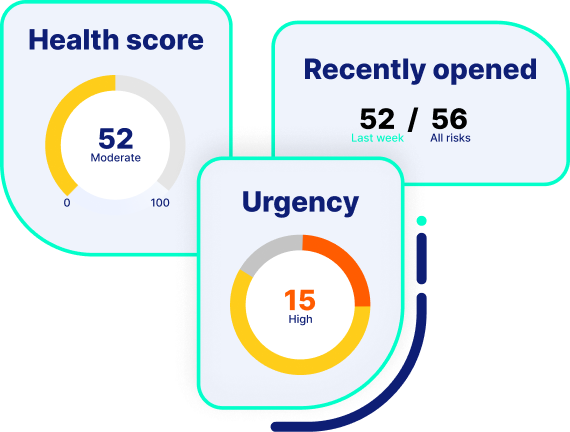
StorageGuard scans, detects, and fixes security misconfigurations and vulnerabilities across hundreds of storage, backup and data protection systems – including Dell EMC, NetApp, Hitachi Vantara, Pure, Rubrik, Commvault, Veritas NetBackup, HP, Brocade, Cisco, Veeam, Cohesity, IBM, Infinidat, VMware, AWS and Azure.
.
- Visibility. Detect all security misconfigurations and vulnerabilities in your storage, backup & data protection systems
- Prioritization. Act upon your most urgent security misconfigurations and vulnerabilities, where you’re most at risk
- Protection. Ensure all your storage & backup systems can withstand ransomware and other attacks, to prevent data loss
- Compliance. Guarantee your storage, backup and data protection systems are compliant with security regulations and standards
On September 27th, Johnson Controls Suffered A Massive Ransomware Attack, Which Included Deleted Backups


What’s our secret sauce?
- We are the ONLY company that can scan storage & backup systems for security vulnerabilities & misconfigurations.
- We have built the most comprehensive Knowledge Base of security risks & best practices for enterprise storage & backup environments.
CISOs Guide To ISO 27040: Storage Security
The release of ISO/IEC 27040:2024 provides an overview, analysis, and guidance for the security of storage & backup systems.

Our Awards

Data Security Solution Provider of the Year

Top 10 Enterprise Security Startups
Vulnerability Management Solution of the Year



Talk To An Expert
It’s time to automate the secure configuration of your storage & backup systems.